
Many organizations have embraced a data-first decision model across their business. This has led to a need for establishing new data teams and data systems designed to support and govern a robust data infrastructure.
Building a successful data team is essential for organizations seeking to leverage data for strategic decision-making. Depending on the size of the organization, smaller teams may end up combining data roles into one, while larger organizations may have multiple roles. The key to an expert orchestration in a data-first organization is to recognize the differences in each data field while also ensuring effective collaboration and communication across the different roles. While many of the roles do share some knowledge and skills overlap, there are many distinct differences in the technical capabilities of each that must be understood to be successful.
We will discuss the responsibilities, differences, and skillset overlap of a variety of core data roles including a data architect, data engineer, database administrator, data scientist, and data analyst. Most importantly, we’ll explore how organizations can avoid common pitfalls while building a cohesive data team.
The Architecture of a Data Team
The figure below helps visualize some common skills and the overlap between each role. This is not meant to be a comprehensive list of all skills, just a visual depiction of some similarities and differences.
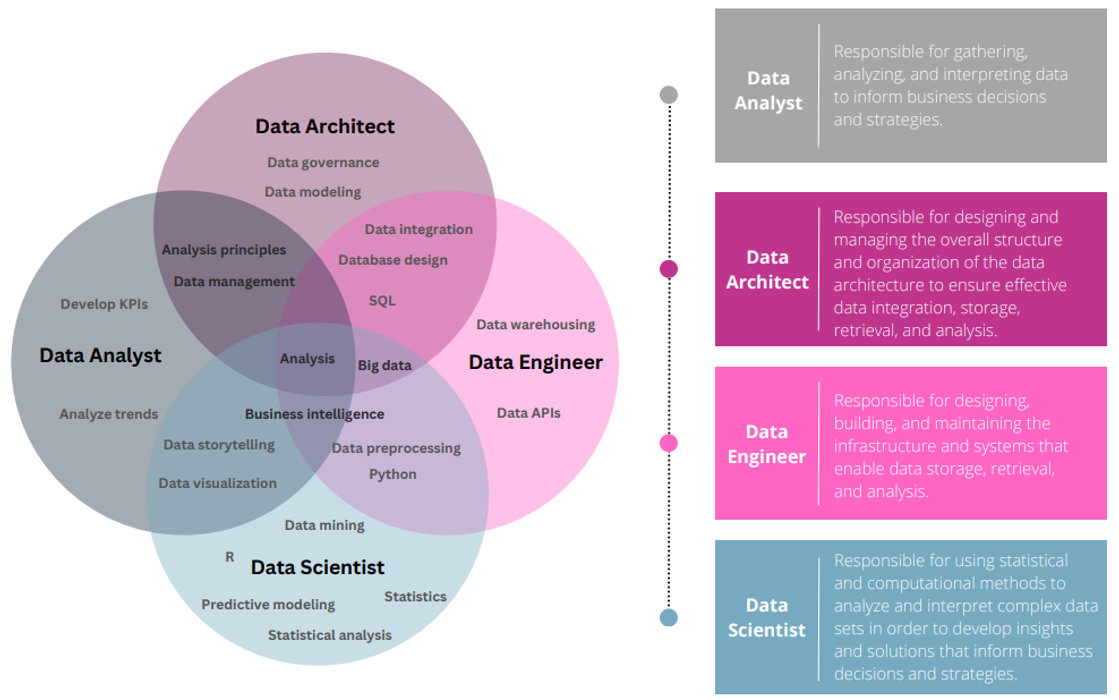
The Data Architect
A data architect handles planning, designing, and managing the structure and architecture of an organization’s data and its data tools tech stack. They work with business stakeholders and other members of the data team to ensure that the data architecture aligns with the organization’s objectives. Data Architects are also responsible for overseeing the implementation of data governance policies and procedures to ensure the accuracy, consistency, and security of the data.
Data Engineer
Data engineers are responsible for building and maintaining the infrastructure required to support data storage, processing, and analysis. This is often a misunderstood role and shares some overlap with the data architect and database administrator. They work closely with data architects to ensure that the infrastructure is designed to support the organization’s data requirements and strategy. They also collaborate with data scientists and data analysts to ensure that the data is available and accessible for the types of ongoing analysis that might be required. This role should not be confused with a traditional developer in that its function is to develop and maintain the data models.
Database Administrator
Also often confused with engineers and architects, database administrators specialize in database management and are proficient in SQL, Spark, and Python. They often specialize or get certified in one database, for example Redshift, Azure, BigQuery, and Snowflake; but it is growing more common to have a database administrator that can work across multiple ecosystems.
Data Scientist
Data scientists are responsible for using statistical and machine learning techniques to analyze data and derive insights that can be used to inform strategic decision-making. They work with business stakeholders to understand and define objectives, identify key questions and hypotheses that can be tested using data. They also collaborate with data engineers and data analysts to ensure that the data is cleaned, transformed, and prepared for analysis.
The Data Scientist is a misunderstood role because they too are often tasked with database administration and engineer duties. This may be suitable for some smaller organizations, but to benefit from the skills of a data scientist, it is important to ensure they are free from having to organize and manage database architectures to create models to help extract value from the data.
Data Analyst
Data analysts are responsible for analyzing data to identify patterns and trends that can be used to inform decision-making. They work closely with business stakeholders to understand their data needs and develop reports and dashboards that provide insights into key metrics and KPIs. They also collaborate with data engineers and data scientists to ensure that the data is available and accessible for analysis.
Often misclassified as an entry-level or lower-level role, the data analyst’s function is to develop reporting and deep analysis of the data. This role is often the closest to the data and is often called upon to validate and check the data quality and are the first line of defense when troubleshooting bugs.
Where Organizations Get It Wrong
One common mistake that organizations make when building a data team is to assume that all members of the team have the same skills and expertise. This can lead to a lack of understanding and appreciation for the unique responsibilities and differences between each role. Assuming that people in these roles all possess the same skills or have a broad range of knowledge and skills can cause some limitations. For example, lets imagine a contractor tasked with building a house. An experienced contractor would not do so single-handedly. This would lead to time-delays and quality issues. Building a house correctly requires different tasks, which require vastly different skills. It is much more efficient to have a team of people working together. Each person can specialize in a specific role, like plumbing or carpentry, and work together to complete the job more efficiently and produce a better-quality product.
If an organization assumes that a data analyst and a data scientist have the same responsibilities, they may fail to leverage the data scientists advanced statistical and machine learning expertise and extract unique value from data. Likewise, if a data engineer and a database administrator are assumed to have the same responsibilities, this could lead to a failure in providing the necessary resources to ensure database performance and security. Many times, like that of our inexperienced contractor, this results in poor data quality and limits the organization’s ability to make accurate and timely data-driven decisions.
In addition, many smaller organizations may fail to provide adequate support and resources for continuing education. Data technology is constantly advancing, and it’s crucial for members of the data team to stay up to date with the latest skills.
Lastly, misunderstanding the differences in these roles increases the risk of creating a jack-of-all-trades, master of none. This could fuel an environment where people in these roles spread themselves too thin across multiple specialties. Of course, it is tempting to create one data role that blankets all specialties; however, this can also dilute proficiency in each category, preventing mastery in any one area. That person will need to invest time and effort in addition to the already essential continuing education needed to maintain a single data role, to acquire the necessary skills and knowledge from the other roles. This can significantly slow down overall progress and risk the quality of the organizations data and data infrastructure.
Principles of Developing a Successful Data Team
Success in building a success and cohesive data team can be achieved with effective communication and collaboration across the team. To do this, organizations should:
- Clearly define each data role and its core responsibilities.
- Promote open communication and collaboration.
- Ensure an understanding of the organization’s objectives and how data can help achieve those objectives.
- Provide opportunities for cross-functional training and education to build an understanding for the unique responsibilities of each role, and to help position your team to be masters in their field.
Managing data is not a small task and requires many individuals with a comprehensive set of skills. For smaller organizations, it might make sense to outsource these capabilities, but for larger organizations it’s important to create a cohesive team with individualized skills including a data architect, data engineer, database administrator, data scientist and a data analyst.