
Marketing segmentation is essential for every brand, and it is especially important for better understanding the needs of a target audience. Segmentation involves “identifying distinct [groups] of buyers by [examining] demographic, psychographic, and behavioral differences between them” (Kotler 2001). Doing so allows marketers to select groups with the greatest opportunity for their business and better align their product or service offerings to fit the needs of each distinct group.
For certain industries such as technology, those needs may tend to shift more rapidly than other industries. With that, the need to revise what qualifies each segment may also occur more frequently. Fortunately, the growing availability of consumer data and advancements in computing power gives marketers the ability to classify their audience regularly or any time they anticipate a shift in demand or needs.
The following is a data scientist’s take on the segmentation process. The data scientist has many unsupervised and supervised machine learning techniques at our disposal, all of which are not only capable of segmenting audiences by their broader basic demographic attributes such as age or income, but also segment by more granular features such as time spent on a particular section of a website or how recent and frequent individuals viewed a certain page.
Specifically, this blog aims to highlight the importance of feature scaling to improve the audience segmentation classification.
What do we mean when we say feature scaling?
Let’s say we have a dataset of the following attributes, age, pageviews and income:
Each of these attribute values are on relatively different scales; age would have a minimum and maximum value that is quite different than the minimum and maximum of income. These differences in magnitude tend to directly influence the modeling process. Generally, features on a larger scale will have a greater effect on the fit of the model and larger magnitude attributes will tend to be more important and the effect of the smaller magnitude features will be lost.
Feature scaling allows us to normalize the values of each attribute and put them on scales of similar magnitudes which help mitigate the problems during modeling. Scaling can be done several ways, but the most common techniques are transforming values into a range between 0 and 1, or a process called standardization which removes the mean and scales to unit variance – this is the same way we would derive a z-score.
Let’s look at the procedure and see how it affects the accuracy of our model.
What does feature scaling look like?
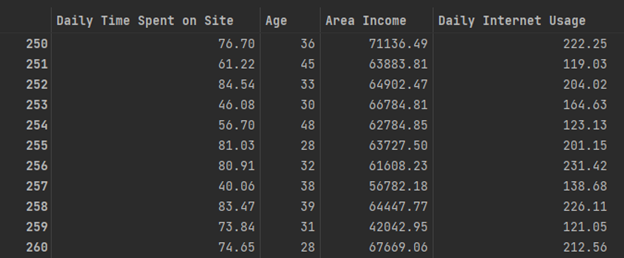
Below we have a set of non-normalized features that we will use to segment our audience into those who have converted and those who have not. Notice that income and age are on drastically different scales.
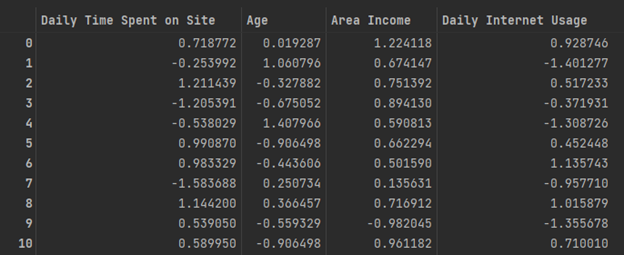
After scaling the features to their z-score, the features are now on similar scales.
Why does this matter?
Attributes with different magnitude scales tend to negatively impact the accuracy of our models – let’s see how.
Below are the results of two separate models, each using the same supervised learning algorithm to classify whether a person is part of those who converted, and those who did not.
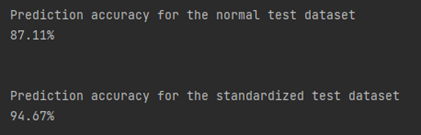
Accuracy is defined as the ratio of the predictions the model got right over the total set of predictions. Here we can see that the accuracy of our model fit using unscaled features is approximately 87% – this means our model correctly predicted whether a person converted 87% of the time. On the other hand, our model predictions using standardized data was correct approximately 95% of the time.
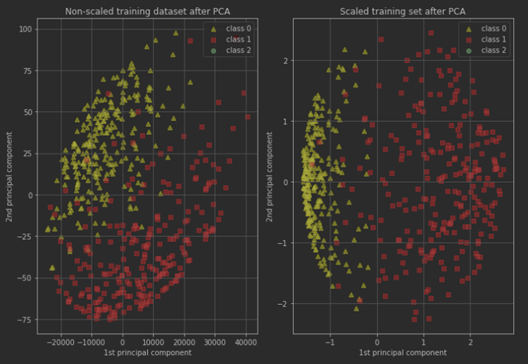
Below we visualize how we achieve this performance improvement. After performing a principal components analysis, which is a feature reduction technique that allows us to extract components derived from our original features which explain as much of their combined variance as possible gives us the following:
Putting the data to work
These relatively simple techniques yield a large performance improvement for our model with relatively low preprocessing costs. Applying these techniques during marketing segmentation can also help marketers understand their audiences better and more accurately classify each of them which can lead to more conversions.
References
Kotler, K. (2001). A framework of marketing management. Prentice Hall